Introduction
PostgreSQL is renowned for its robustness and reliability, making it a go-to choice for a wide range of applications. To ensure your PostgreSQL database performs at its best, benchmarking is a crucial step in the process. In this blog post, I will delve into the powerful capabilities of pgbench, a versatile tool for running benchmark tests on PostgreSQL.
Out of the box, pgbench uses a scenario loosely based on TPC-B, running a sequence of five SELECT, UPDATE, and INSERT commands per transaction. While this default scenario provides valuable insights into your system’s performance, there are cases where more specialized testing is necessary.
In this blog, I will explore the art of crafting customized benchmarks using specific tables and SQL statements. This approach enables you to tailor your benchmark to the unique demands of your application, ensuring your PostgreSQL database is optimized for real-world workloads.
Create an EC2
Create an Amazon EC2 running Amazon Linux. These instructions use an Instance type of t2.2xlarge with the below configuration:
cat /etc/image-id
image_name="al2023-ami"
image_version="2023"
image_arch="x86_64"
image_file="al2023-ami-2023.2.20231016.0-kernel-6.1-x86_64.xfs.gpt"
image_stamp="f733-4bf8"
image_date="20231016220519"
recipe_name="al2023 ami"
recipe_id="ed84f07e-e06c-a3cd-759b-d254-59e2-3d69-b61eb10b"
Please note that amazon-linux-extras is not available for Amazon Linux 2023.
Install postgresql15
Install postgresql15 with the following command
sudo yum install postgresql15
The output will be similar to:
sudo yum install postgresql15
Last metadata expiration check: 0:11:01 ago on Mon Oct 23 16:46:45 2023.
Dependencies resolved.
Package Architecture Version Repository Size
.
.
Lines omitted for brevity
.
.
Verifying : postgresql15-private-libs-15.0-1.amzn2023.0.4.x86_64 2/2
Installed:
postgresql15-15.0-1.amzn2023.0.4.x86_64 postgresql15-private-libs-15.0-1.amzn2023.0.4.x86_64
Complete!
Install postgresql-contrib package
This package contains various extension modules that are included in the PostgreSQL distribution including pgbench. Install the package with the following command:
sudo yum install postgresql15-contrib
The output will be similar to:
sudo yum install postgresql15-contrib
Last metadata expiration check: 0:32:28 ago on Mon Oct 23 16:46:45 2023.
Dependencies resolved.
.
.
Lines omitted for brevity
.
.
Verifying : uuid-1.6.2-50.amzn2023.0.2.x86_64 3/3
Installed:
libxslt-1.1.34-5.amzn2023.0.2.x86_64 postgresql15-contrib-15.0-1.amzn2023.0.4.x86_64 uuid-1.6.2-50.amzn2023.0.2.x86_64
Complete!
Verify that pgbench has been installed:
which pgbench
Output:
/usr/bin/pgbench
Create a working directory/folder
Create a working directory for pgbench related artifacts
mkdir pgbench; cd pgbench
Create a database for pgbench
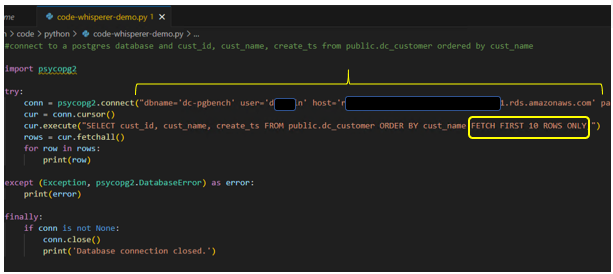
For the purpose of this testing, I will be creating a new database named pg-bench. Log on as the RDS administrator and run the below commands:
CREATE DATABASE "dc-pgbench"
WITH
OWNER = dbadmin
ENCODING = 'UTF8'
LC_COLLATE = 'en_US.UTF-8'
LC_CTYPE = 'en_US.UTF-8'
TABLESPACE = pg_default
CONNECTION LIMIT = -1
IS_TEMPLATE = False;
Connect to this new database and create a user for pgbench with the following commands:
create user dcpgbench with encrypted password 'mypassword';
grant all privileges on database "dc-pgbench" to dcpgbench;
Confirm connectivity to the Postgres RDS instance
In the pgbench directory, create the below file to facilitate logging on to the database without having to type a long command:
Edit a file
vi psql.ksh
Enter the below commands after modifying for your instance:
export PGB_HOST=red-primary-writer.xxxxx.us-east-1.rds.amazonaws.com
export PGB_PORT=5432
export PGB_DB=dc-pgbench
export PGB_USER=dcpgbench
PGPASSWORD=mypassword psql --host=$PGB_HOST --port=$PGB_PORT --username=$PGB_USER --dbname=$PGB_DB
Change permissions
chmod u+x psql.ksh
Test connectivity
./psql.ksh
If successful, the connection will look like:
psql (15.0, server 14.6)
SSL connection (protocol: TLSv1.2, cipher: AES128-SHA256, compression: off)
Type "help" for help.
dc-pgbench=> SELECT current_database();
current_database
------------------
dc-pgbench
(1 row)
dc-pgbench=>
I also issued the command
SELECT current_database();
To confirm that I am connected to the correct database.
Create a data structures that will be used to stress test the database instance
I will be using the below structures to create a load on the database. The workload will be executed by user dcpgbench.
Sequences for keys
The below sequences will be used to generate customer, order and, item data respectively:
CREATE SEQUENCE if not exists dc_cust_id
INCREMENT 1
START 1
MINVALUE 1
MAXVALUE 9223372036854775807
CACHE 1;
CREATE SEQUENCE if not exists dc_order_id
INCREMENT 1
START 1
MINVALUE 1
MAXVALUE 9223372036854775807
CACHE 1;
CREATE SEQUENCE if not exists dc_item_id
INCREMENT 1
START 1
MINVALUE 1
MAXVALUE 9223372036854775807
CACHE 1;
GRANT USAGE ON SEQUENCE dc_cust_id TO dcpgbench;
GRANT USAGE ON SEQUENCE dc_order_id TO dcpgbench;
GRANT USAGE ON SEQUENCE dc_item_id TO dcpgbench;
Tables
The below tables will store customer, items and order data respectively:
CREATE TABLE dc_customer
(
cust_id BIGINT NOT NULL,
cust_name VARCHAR(60) NOT NULL,
create_ts timestamp(0) without TIME zone NOT NULL,
CONSTRAINT dc_cust_pk PRIMARY KEY (cust_id)
)
;
CREATE TABLE dc_item
(
item_id BIGINT NOT NULL,
item_name VARCHAR(60) NOT NULL,
create_ts timestamp(0) without TIME zone NOT NULL,
CONSTRAINT dc_item_pk PRIMARY KEY (item_id)
)
;
CREATE TABLE dc_order
(
order_id BIGINT NOT NULL,
cust_id BIGINT NOT NULL references dc_customer (cust_id),
item_id BIGINT NOT NULL references dc_item (item_id),
quantity BIGINT NOT NULL,
create_ts timestamp(0) without TIME zone NOT NULL,
CONSTRAINT dc_order_pk PRIMARY KEY (order_id)
)
;
GRANT SELECT, INSERT, UPDATE, DELETE
ON dc_customer, dc_item, dc_order
TO dcpgbench
;
Load test 01 – Write intensive
I will be using the below script to perform a load test. At a high level, this test will create data in our three tables simulating writes. This data will then be used in a later script to simulate read intensive data.
Command to execute the script
Execute the script with the below command
nohup ./load-test-01.ksh > load-test-01.out 2>&1 &
Contents of the script
Below are the contents of the script with comments on each line of code
#!/bin/bash
#
## database endpoint
#
export PGB_HOST=red-primary-writer.xxxxx.us-east-1.rds.amazonaws.com
#
## database port
#
export PGB_PORT=5432
#
## bench mark database
#
export PGB_DB=dc-pgbench
#
## The user name to connect as
#
export PGB_USER=dcpgbench
#
## Number of clients simulated, that is, number of concurrent database sessions
#
export PGB_CLIENTS=50
#
## Number of worker threads within pgbench
#
export PGB_THREADS=20
#
## filename containing the SQLs to be executed
#
export PGB_SQL_FILE=load_test_01.sql
#
## Run the test for this many seconds
#
export PGB_RUN_TIME=300
#
## Set the filename prefix for the log files created by --log
#
export PGB_LOG_PREFIX=dc-pgb
#
## Sampling rate, used when writing data into the log, to reduce the
## amount of log generated. 1.0 means all transactions will be logged,
## 0.05 means only 5% of the transactions will be logged
#
export PGB_SAMPLE_RATE=0.05
#
## make sure we are in the correct directory
#
cd /home/ec2-user/pgbench
#
## run the test
#
PGPASSWORD=mypassword pgbench --client=$PGB_CLIENTS --jobs=$PGB_THREADS --time=$PGB_RUN_TIME --username=$PGB_USER -d $PGB_DB --host=$PGB_HOST --port=$PGB_PORT --file=$PGB_SQL_FILE --log --log-prefix
=$PGB_LOG_PREFIX --sampling-rate=$PGB_SAMPLE_RATE --no-vacuum
Contents of the SQL to generate write activity
The following SQL commands will be executed to generate some load on the database. These SQL statements will be saved in file named load_test_01.sql which will be referenced by the script named load-test-01.ksh.
--
--get the next sequence value for the order id and
--item id
--
SELECT nextval('dc_cust_id') \gset cust_id_
SELECT nextval('dc_item_id') \gset item_id_
--
--Create a random value from the MMSS of the current
--timestamp to be used as an order quaintity
--
SELECT cast(substring(TO_CHAR(CURRENT_TIMESTAMP, 'YYYY-MM-DD HH12:MMSS') from 15 for 4) as int) as order_qty \gset
--
--Insert a row into the customer table
--
INSERT
INTO dc_customer
(
cust_id,
cust_name,
create_ts
)
values
(
:cust_id_nextval,
concat('cust-',CURRENT_TIMESTAMP),
CURRENT_TIMESTAMP
)
;
--
--Insert a row into the item table
--
INSERT
INTO dc_item
(
item_id,
item_name,
create_ts
)
values
(
:item_id_nextval,
concat('item-',CURRENT_TIMESTAMP),
CURRENT_TIMESTAMP
)
;
--
--Insert a row into the order table
--
INSERT
INTO dc_order
(
order_id,
cust_id,
item_id,
quantity,
create_ts
)
values
(
nextval('dc_order_id'),
:cust_id_nextval,
:item_id_nextval,
:order_qty,
CURRENT_TIMESTAMP
)
;
Load test 02 – Read intensive
I will be using the below script to perform a read load test. At a high level, this test will perform multiple reads on our three tables. The previous test has written approximately 150,000 rows to our three test tables.
Command to execute the script
Execute the script with the below command
nohup ./load-test-02.ksh > load-test-02.out >2&1 &
Contents of the script
Below are the contents of the script with comments on each line of code
#!/bin/bash
#
## database endpoint
#
export PGB_HOST=red-primary-writer.xxxxx.us-east-1.rds.amazonaws.com
#
## database port
#
export PGB_PORT=5432
#
## bench mark database
#
export PGB_DB=dc-pgbench
#
## The user name to connect as
#
export PGB_USER=dcpgbench
#
## Number of clients simulated, that is, number of concurrent database sessions
#
export PGB_CLIENTS=200
#
## Number of worker threads within pgbench
#
export PGB_THREADS=20
#
## filename containing the SQLs to be executed
#
export PGB_SQL_FILE=load_test_02.sql
#
## Run the test for this many seconds
#
export PGB_RUN_TIME=300
#
## make sure we are in the correct directory
#
cd /home/ec2-user/pgbench
#
## run the test
#
PGPASSWORD=mypassword pgbench --client=$PGB_CLIENTS --jobs=$PGB_THREADS --time=$PGB_RUN_TIME --username=$PGB_USER -d $PGB_DB --host=$PGB_HOST --port=$PGB_PORT --file=$PGB_SQL_FILE --no-vacuum
Contents of the SQL to generate read activity
The plan for this script is to select random data from our three tables. These SQL statements will be saved in file named load_test_01.sql which will be referenced by the script named load-test-01.ksh .
First, I establish the current value of the sequences with the below SQLs:
SELECT last_value FROM dc_cust_id;
SELECT last_value FROM dc_item_id;
SELECT last_value FROM dc_order_id;
Each of the sequences is current at a value of approximately 151,000 and hence I will use 150,000 as the upper range in the below random function.
SELECT floor(random()*(150000)) as dc_cust_id \gset
--
--select the orders
--
select
cus.cust_id
,cus.cust_name
,itm.item_id
,itm.item_name
,ord.order_id
,ord.quantity
,ord.create_ts
from dc_order ord
inner join dc_customer cus
on cus.cust_id = ord.cust_id
inner join dc_item itm
on itm.item_id = ord.item_id
where cus.cust_id = :dc_cust_id
order by
cus.cust_id
,ord.create_ts
;
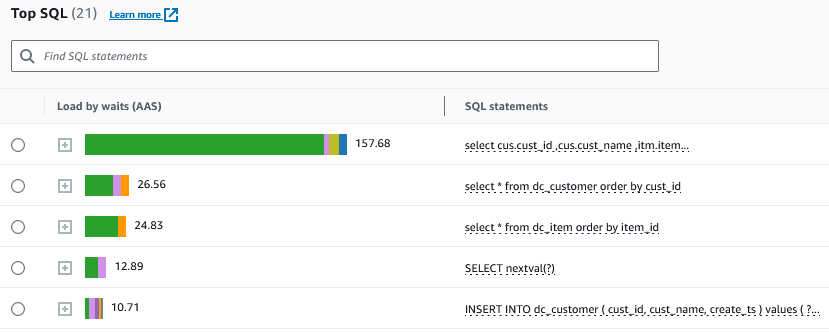
Monitoring the activity – Performance Insights
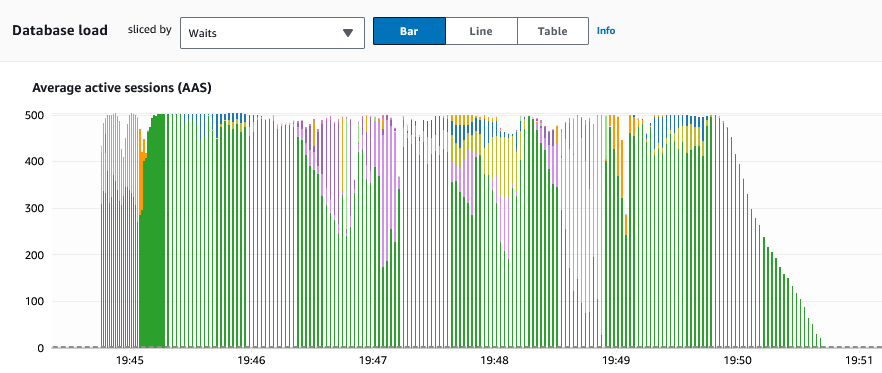
The impact of the test can be measured by Performance Insights. I ran a test with PGB_CLIENTS set to 500 users for a period of 5 minutes. The Average active sessions (AAS) displayed this spike in Performance insights as a result of the load placed on the database:
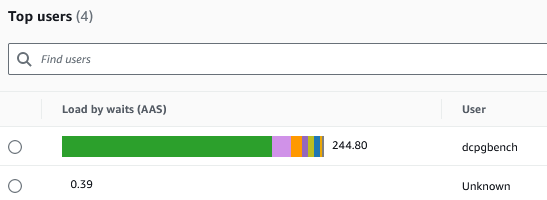
As expected the top user was dcpgbench, the user running the workload:
The top SQLs reported by Performance Insights also list the SQL statements that I was executing